RFC 288 - MIR - Control Flow Graph
Categories:
Control Flow Graph Intermediate Representation
This RFC proposes using a Control Flow Graph (CFG) IR as a stage between the AST and LLVM forms, because it will help simplify the implementation of key Bramble features: including consistency semantics, ownership rules a la Rust, and automatic injection of destructors for values.
Bramble’s MIR language design was inspired by Rust’s MIR and the design of the conversion from AST to MIR was inspired by LLVM.
Problem
Bramble needs to perform data flow analysis on each function in a program. The analyses needed are: consistency rules checking, automatic insertion of destructors for values, and ownership rules. More analyses may be added in the future.
For each of these analyses, Bramble needs to look at the sequence of operations that are applied to one or more locations in memory, then determine if every possible sequence of operations satisfy some given set of rules. This is falls under dataflow analysis.
While an AST can be used for such analyses, it is not well suited and would make implementation of the analyses more complex.
Requirements
- Simplify the forms of analysis which follow a “dataflow” paradigm.
- Be able to lower into LLVM IR.
- Integrate with Thorn Insights platform.
- Be able to represent all Bramble programs in a MIR form.
- MIR representations must be fully independent of the preceding AST representation. This means that the AST form of a Bramble program could be deleted after conversion to MIR and the compilation will always be able to complete successfully.
- Allow for intra-procedure (local) optimizations.
Solution
Rather than use the AST IR for dataflow analyses, create a new Control Flow Graph IR (henceforth referred to as a MIR), and all dataflow analyses are done against this form rather than the AST form.
The AST will be “lowered” into the MIR form after parsing and type resolution and before transformation into the LLVM IR form. After being lowered, any analyses and optimizations which work best with a CFG are applied. Then the MIR is lowered into LLVM IR form and compilation continues with the LLVM compiler toolset.
Alternatives
The alternative solution is to continue using an AST for all compiler analyses and optimizations. Most compilers do their work off an AST form and only use CFG forms for optional optimizations or linting. The Rust compiler currently uses a CFG IR form as an intermediate step between the AST and LLVM IR; however, its earliest versions used only an AST and the CFG IR was added later to help simplify the ownership rules analysis.
The reason to continue using the AST for all analysis rather than the MIR is to save development time and simplify the implementation of rules and optimizations that focus on the flow of data. It is a fact that all analyses that work on the CFG IR model will work on an AST, but their implementation may be much more complex and fragile.
Problems with using an AST for this analysis include the following. First, all these analyses need to validate some rule holds for one or more variables through every possible path of execution, the AST form makes it difficult to correlate all the different paths when there are branches. Second, the AST form recursively embeds operators as children of operators, this makes it difficult to find the leaf operands (specifically the variables being used), because the desired analyses are focused largely on tracking how each specific variable is used, being able to easily extract those variables from operations is critical for easy implementation. Third, all these analyses will want to know what unbroken chain of operations must be applied to a set of variables (Basic Block), this information is difficult to extract from an AST. All this information is encoded in the AST form, but the AST form prioritizes preserving the hierarchy of operations, which obfuscates the information that the dataflow analyses require; this leads to the implementaion of analyzers being more complex.
The ulimate price of the increased complexity of implentation is reducing the power of the analyzers. As experienced by the Rust team when the lifetime checker was implemented on an AST: having a less powerful analyzer means more blunt enforcement of the rules. This pushes more burden onto the user of the language. In the case of Rust, the “more blunt” analyzer meant that it could not understand more complex or subtle memory operations and would fail code that was technically correct. Using the AST as the basis for dataflow analysis, leads to simpler analyzers, which leads to more false negatives, forcing users to write worse code.
I chose to implement the MIR because significantly reducing the complexity and fragility of the dataflow analyses will be a net long-term benefit for the Bramble compiler. The consistency rules system could be incredibly complex, as it evolves, and a CFG IR model will greatly reduce the complexity of its implementation. Further, many optimizations benefit from the CFG IR model and implementing one now will allow me to start safely adding optimizations to Bramble. Finally, this decision was influenced by taking advantage of Rust’s experience: using the AST IR form greatly limited the power of ownership rules system and moving to a CFG IR was critical for building a more powerful and useable ownership rules model. Given that the consistency rules model that Bramble will implement shares many mathematical fundamentals with Rust’s ownership model and lifetime model; Rust’s experience provides valid insight into a major pitfall Bramble could suffer.
Design
MIR Architecture Model
The Bramble MIR’s design represents a simplified model of the physical memory and CPU instructions. MIR breaks memory down into 3 locations, based upon their lifetime relative to the execution of a program: static, heap, and stack. All operations in the MIR correspond to a subset of the instructions on a CPU and, like a CPU, the results of each single operation must be stored somewhere before being used in a subsequent operation. Further, in MIR, operations are a linear sequence and have no hierarchy.
Static memory represents the “.data” and “.code” (For x86) sections of a program, which correspond the parts of memory where data lives from the moment the program begins execution to when it stops execution. In MIR, the representations of each function are stored in the “Static” memory group. Heap memory corresponds to the heap, and data here will live from the moment it is explicitly allocated until it is explicitly deallocated (currently, no constructs in MIR correspond to or represent heap data). Stack memory, or local memory, corresponds to the stack frame of a function: data in this section will be valid from the moment a function is entered to the moment that instance of the function exits. In MIR, all variables defined within a function (user and temporary) are stored on the stack.
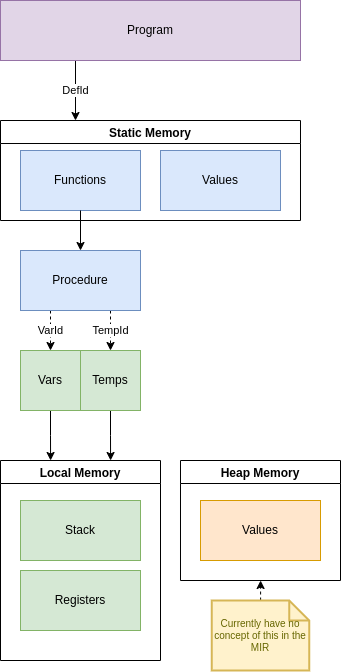
MIR Components
When lowered into its MIR form, a project is represented as a single MirProgram, which represents all the functions and types in the project. Each function is defined as a set of Basic Blocks. Each user defined type is stored as an ordered set of fields, where each field has a name and a type.
A Basic Block represent the largest set of operations where: if one operation is executed they are all executed and every operation is executed immediately after the preceding operation. Every Basic Block is composed of 0 or more Statements and a Terminator. The Statements represent operations that have results that are stored in memory. Terminators tell where the program will go after the last Statement in the Basic Block is executed.
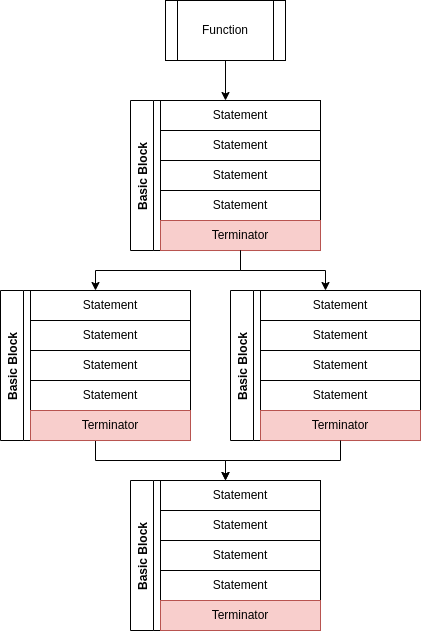
A visualizaiton of how a function with an If Expression would be represented via Basic Blocks. Each Basic Block is an ordered set of statements ending with a Terminator. The Terminator determines what the next Basic Block to be executed will be.
There is a single statement: Assign. This statement executes an operation and stores the result in a location in memory; this location can be either a user defined variable or a temporary variable for intermediate results. The operations correspond to unary and binary arithmetic instructions available on the CPU. Operations take one or two operands; operands can be either constants or specific locations in memory. Data can only be stored and read as base types (e.g., i32 or f64). For types constructed from base types (arrays and structs), Accessors are used to access the location of a specific element or field within a value of the constructed type.
The Terminator ends every Basic Block and is always executed. The simplest Terminator is the Return, which tells the program to exit the current function and remove its stack-frame from the stack. The GoTo Terminator tells the program to go to the specified Basic Block within the current function. The Conditional GoTo Terminator tells the program to go to one of two Basic Blocks based upon whether a given conditional value is true or false. Finally, the Call Terminator tells the program to call a function and provides a location to store the result of the function.
Lowering AST to MIR
The design for lowering the AST to the MIR resembles the current design for lowering the AST to LLVM IR. There is a set of MIR types that can represent any Bramble program in MIR and implement a CFG. The lowering process will generate a set of CFGs, composed of MIR values, that each represent a function from the input AST. The process uses a MIR Builder, which constructs the MIR form of a single function, and a Traverser, which traverses the AST and uses the Builder to convert types and functions into MIR forms.
The MirProgram type manages all custom types defined by the user and the MIR representation of each function. This is the final output of the lowering process. Subsequent operations that apply to the MIR will take the MirProgram as input.
The lowering process begins by traversing the AST for every user defined type and adds the type to the Type Table in MirProgram. Types are converted to MIR first, so that when they are encountered while lowering function definitions, their definitions can be easily found. This also separates responsibilities and leads to simpler code.
The Type Table assigns a unique integer identifier to each type and this identifier will be used within the MIR to represent types. This makes representation smaller in memory and makes programming easier and execution faster. Every type is represented by a single integer, so passing to other functions can be done by copying instead of cloning. Likewise, comparison will amount to a single integer comparison instruction. This will also lead to better Rust code.
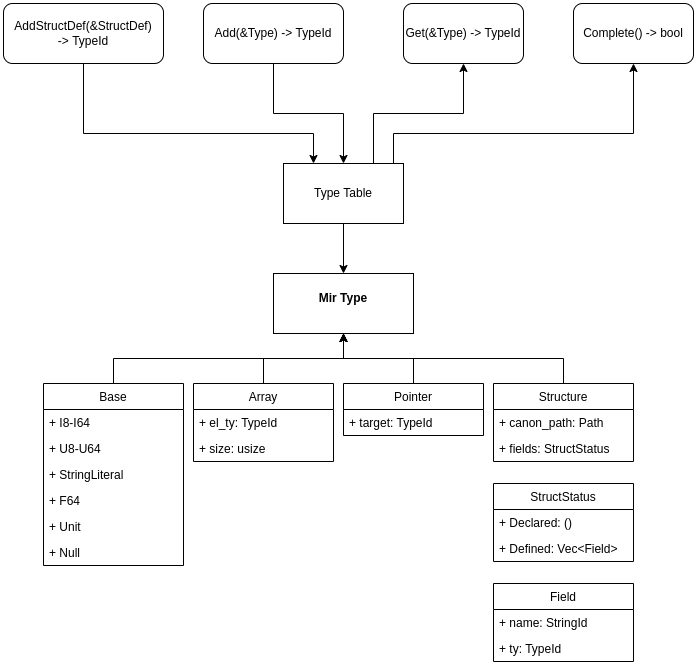
Note: The TypeTable is not strictly required: the MIR could continue to use Paths and the Structure Definitions in the AST form for referencing and looking up types. However, using an integer TypeId to identify types results in significantly simpler Rust code and is a better design overall. By taking this opportunity to add in the TypeTable we can begin to reap the benefits of this design and then, in the future, move the construction of the TypeTable to an earlier stage in the BrambleC pipeline so that the AST also uses TypeIds rather than the cumbersome Type enum.
After all types are lowered to the MIR, the AST is traversed again, and the name and signature of every defined function is added to the set of functions in MirProgram (without the MIR definition of the function). This is because functions are identified using integers in the MIR and we need to know the identifier for every function before lowering the function definitions, otherwise, there may be a call to a function that has not yet been lowered and it will not have an assigned function identifier.
After adding every function name and signature to the MirProgram and assigning them identifiers, the lowering process transforms the definition of each function from an AST to a MIR. A post order traversal of the AST of the function is performed and the Builder type is used to construct the MIR representation. After the function’s AST has been fully traversed the MIR is finalized and added to the MirProgram as the definition of the function. The lowering process is complete when every function has been converted into a MIR form.
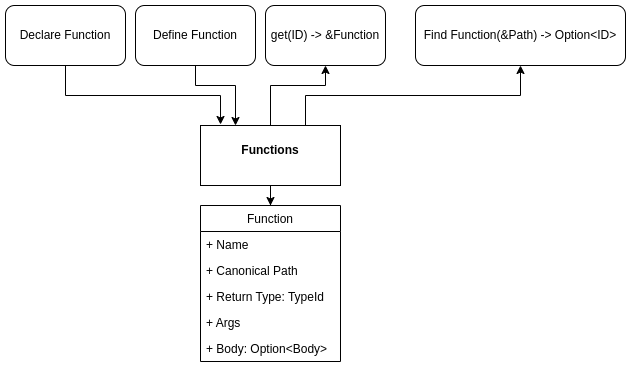
Lowering MIR to LLVM IR
After completing every test and transformation which relies upon the MIR form, the compiler lowers the final MIR into its LLVM form. The lowering process is split into two components: the Traverser and the Builder. The Traverser iterates over each function and custom type, and calls methods on the Builder to construct the LLVM IR. At the completion of the lowering process there will be an LLVM Module that contains all the types and functions in the Bramble project.
The Builder provides a set of methods that correspond to the MIR instruction set. The Traverser calls these methods as it encounters the corresponding MIR instructions. The methods cause the Builder to create the LLVM IR instructions that correspond to the Bramble MIR instructions.
The Builder is responsible for generating the labels for all custom types and all functions, that are used within the LLVM IR and, ultimately, the generated assembly code.
References
The main inspiration for the MIR was from reading through the Rust Compiler source code and this blog post: https://blog.rust-lang.org/2016/04/19/MIR.html. Much of the Bramble MIR design is directly inspired by Rust’s MIR, though a significantly simpler form.
The second source of inspiration was “Engineering a Compiler” by Keith Cooper and Linda Torczan. The chapters on dataflow analysis and control flow graphs directly led me to believe those concepts the best for implementing the consistency rules system for Bramble.
In addition, I looked at Clang and Rosalyn to understand how those compilers used Control Flow Graphs and how they designed their CFG models.
The following links were used during research for the MIR design:
- http://s4.ce.sharif.edu/blog/2019/12/31/clang/
- https://homepages.dcc.ufmg.br/~fernando/classes/dcc888/ementa/slides/ControlFlowGraphs.pdf
- https://eli.thegreenplace.net/2013/09/16/analyzing-function-cfgs-with-llvm
- https://docs.microsoft.com/en-us/dotnet/api/microsoft.codeanalysis.flowanalysis?view=roslyn-dotnet
- https://github.com/dotnet/roslyn-analyzers/blob/main/docs/Writing%20dataflow%20analysis%20based%20analyzers.md
- https://github.com/dotnet/roslyn/blob/1deafee3682da88bf07d1c18521a99f47446cee8/src/Compilers/Core/Portable/Operations/BasicBlock.cs
- https://github.com/rust-lang/rust/blob/f7ec6873ccfbf7dcdbd1908c0857c866b3e7087a/src/librustc/mir/repr.rs
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.