This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Documentation
Bramble is a compiled, statically typed language whose core goal is to develop language abstractions which
allow a developer to explicitly define how they logically want their code to work while acknowledging the
consequences of code be executed by a CPU which exists in the real world.
This goal was inspired while learning the Rust programming language and realizing that lifetime’s in Rust
are semantic representations of the stack frames created by the CPU while executing a program. Rust made
explicit something which was implicit in languages like C and complete hidden in GC languages like Java
and C#. Through lifetimes, Rust guides the developer into explicitly thinking about the physical way a
program is executed. Bramble’s core philosophy is to take this approach as far as possible.
1 - Overview
The Bramble Programming Language
Bramble is a AOT compiled language designed from the gound up to
help developers write optimized, efficient code. There are two
major prongs of design to accomplish this goal:
- Amplification of the mechanics of the actual physical CPU, memory,
and computer.
- Maximum transparency and feedback to what the compiler is doing
and why.
2 - Getting Started
How to build and use Bramble
Instructions for building and using Bramble and Thorn.
Building the Bramble Compiler
Requirements
Rust
Bramble is written in Rust and to build the compiler you will need Rust and Cargo installed.
The easiest way to setup Rust is to get rustup and install the latest
stable toolchain.
LLVM
Bramble uses LLVM as a compiler backend, so you will need to install the LLVM libraries on
your machine. Bramble has been tested against LLVM 11 and 13.
From Source
- You can go to the LLVM site and follow the instructions to build and
install the libraries yourself.
MacOS
Using Homebrew:
brew install llvm
Fedora
Using DNF:
dnf install llvm-devel
Debian & Ubuntu
Follow the instructions provided on this site.
gcc
The Bramble make script, make.sh, uses GCC as a linker between compiled binaries.
Building
After Rust has been installed.
- Clone the Bramble repository:
- Build and test Bramble by running
cargo test. This will build Bramble and execute
all the unit tests.
- Build a release version of Bramble:
cargo build --release
- Execute integration tests: go into the
./tests directory and run ./tests.sh. This will
execute all the integration tests for Bramble and will validate that both the compiler
and LLVM are functioning properly.
- Use
./make.sh to compile and run your own projects.
Hello World
- In the
./tests/scratch/ directory create a file named hello.br.
- Open
hello.br in a text editor and write the following:
fn my_main() -> i64 {
project::std::io::write("Hello World\n");
return 0;
}
- Go to
./tests/ and run ./make.sh -i ./scratch/hello.br. This will compile
and execute hello.br
Using Thorn Insights
Requirements
- Rust: Latest Stable Toolchain
- NodeJS v16+
Building
Thorn insights consists of two components: the thorns server and the
viewer. You run the thorns server from the root of your project directory
and then start the viewer which will connect to thorns and let you
explore your insight data.
Thorns
To install Thorns, clone the GitHub repository and go to the repo directory.
From there run the following:
cd thorns
cargo install --path .
This will create a release build of thorns and install it into the Rust
binaries set.
Then go to your Bramble project root and run thorns. This will automatically
host the insights data that has been output to ./target.
Viewer
After the you have started the thorns server. Go to the Thorns repository
directory and:
cd viewer
npm start
This will start the React based Thorn Viewer, which will connect to thorns
and let you interact with the insights data.
2.1 - The Language
How to learn the language
Documents about the language itself.
Learning the Language
The documentation for the language itself is in the process of being written. Bramble
is currently both very young and very similar to Rust, so it’s easy to learn. As such,
for the launch of this website, the documentation has focused on building the compiler
and unique features of the language (such as Thorn). In the near future, full
documentation will be made for the language but for its current state and to cover
through every evolution.
The best place to start for learning the current Bramble langauge rules is to look
at the large suite of integration tests in the Bramble repository: ./tests/src.
These integration tests are categorized by the language feature they are testing. So,
they give both a reference for all the features and examples of how to use those
features.
2.2 - Testing Bramble
How to test the compiler.
How to test the compiler source code.
The Bramble project comes with a suite of testing tools to help
make the development process easy.
The tests are broken down into three categories: unit tests, integration
tests, and fuzz testing. Integration tests are tests which compile and execute Bramble
source code and validate the output. The Fuzz tester is a specially
built tool which randomly generates Bramble source code for the Bramble
compiler.
Unit Tests
The unit tests for Bramble are all included in the Rust source code,
and can be identified by the source code file name containing the word
test. Unit test modules are kept in the same directory as the module
they are testing, rather than in a fully separate test module.
To run the Bramble unit tests, use the Cargo test command:
cargo test
If you want to run the tests against the release build:
cargo test --release
Integration Tests
All integration tests are run via a shell script; this makes it easy to
run all the integration tests. The shell script will build a release
version of Bramble and use that binary for all integration tests. The
release build is used to make execution of the tests as fast as possible.
The integration tests are all stored in the ./tests with the source code
for each test stored in ./tests/src and the scripts to run the tests in
./tests/. There are about 100 integration tests under the ./tests/src/
directory which the integration test will use for validation.
To run the integration tests, go to ./tests/ and then run ./test.sh.
There are three types of integration tests:
- Positive integration tests: these test that features build and run
correctly.
- Failure tests: these test compiler errors.
- Import tests: these test the compiler importing one Bramble project into
another Bramble project.
Adding an Integration Test
All that is necessary to create a new integration test is to add the following
files to the ./tests/src directory.
Integration tests consist of 2 to 3 parts:
- The test file or project itself. This is one or more Bramble source code
files.
- The expected output file. This what the test source code should output if
it runs correctly. This file has the same name as the test code but with
.out as the extension.
- Optionally, input data for tests that read from the console. This file
has the test name with
.in as the extension.
The test.sh script will automatically detect and execute your file. If you inlude
an input file then the script will automatically pipe each line from the .in
file to your test project.
Fuzz Testing
Testing all the possible syntactically valid Bramble expressions would be
incredibly difficult if done manually. To avoid that work, a special Fuzz testing
tool was written which randomly generates both syntactically valid and invalid
Bramble code and tests that the compiler correctly handles it. Valid code should
parse successfully and invalid code should generate a compiler error.
To run the fuzz tester:
cd ./tests
./test-syntax.sh
Currently, this only tests syntax and not semantics. The code it randomly
generates will have undefined variables, functions, etc. As such, this fuzz tester
only tests that Bramble can parse the code. The next step
for the fuzz testing tool is to build a fuzz tester that generates semantically
valid code which can fully compile and be executed.
3 - Thorn
The Thorn Insights Platform
How Thorn provides deep insights into what the Bramble compiler is doing.
Thorn is the insights platform that enables exploration into exactly what
the Bramble compiler does with your code and why. It is inspired by the question
of what would happen if a compiler was built with the goal of providing
Compiler Explorer out of the box and times a thousand.
Currently, Thorn is in the MVP stage. It comprises a small project server
that allows queries into the audit data generated by the Bramble compiler
when insight recording is turned on and a web front end that allows you
to explore that data in a pleasant visual form.
To tell Bramble to generate a Thorn insight record, simply add this CLI
parameter: --json-trace. The Bramble compiler will then save a JSON
file with the full insight record to the ./target/ directory.
Thorn Features
-
Here’s a visualization of the AST generated by the Bramble
Compiler for a small program:
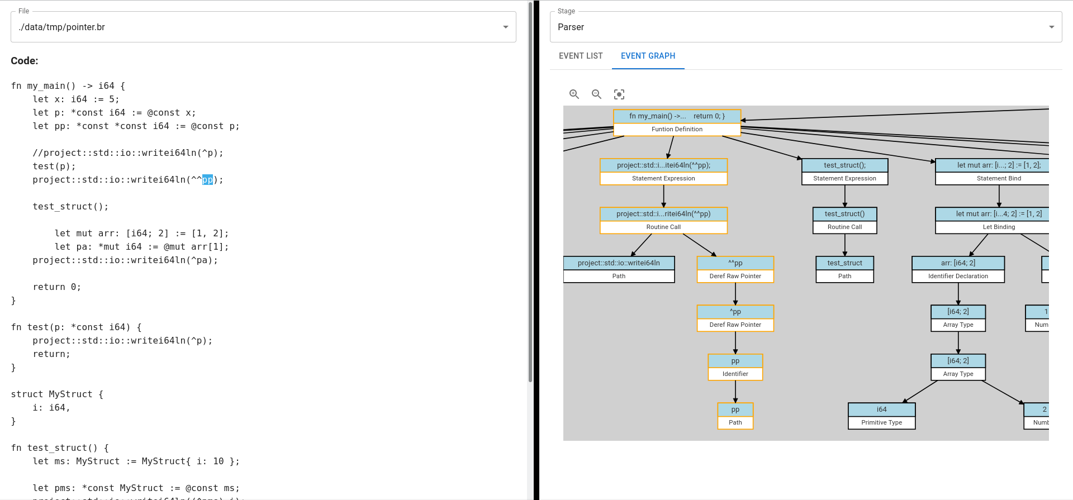
The user has selected an expression and the corresponding subtree has
been highlighted. Helping the viewer investigate how the compiler sees
their code.
-
And here’s an example of the type resolution for every expression in a
program:
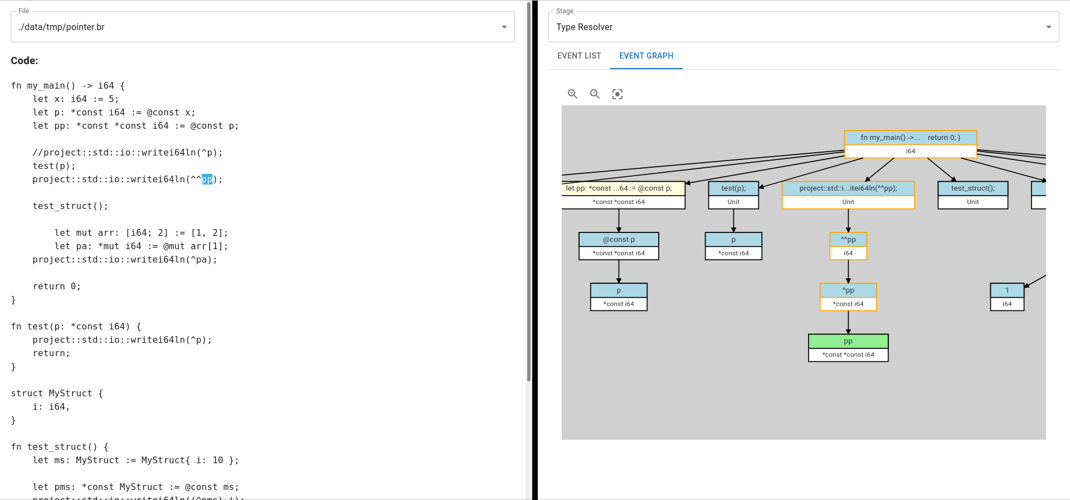
Here, Thorn provides a breakdown of how the type of the selected expression
was resolved. The declaration of `pp` is highlighted in yellow to tell
the user that Bramble used the delcaration to provide context when it was
resolving the type.
-
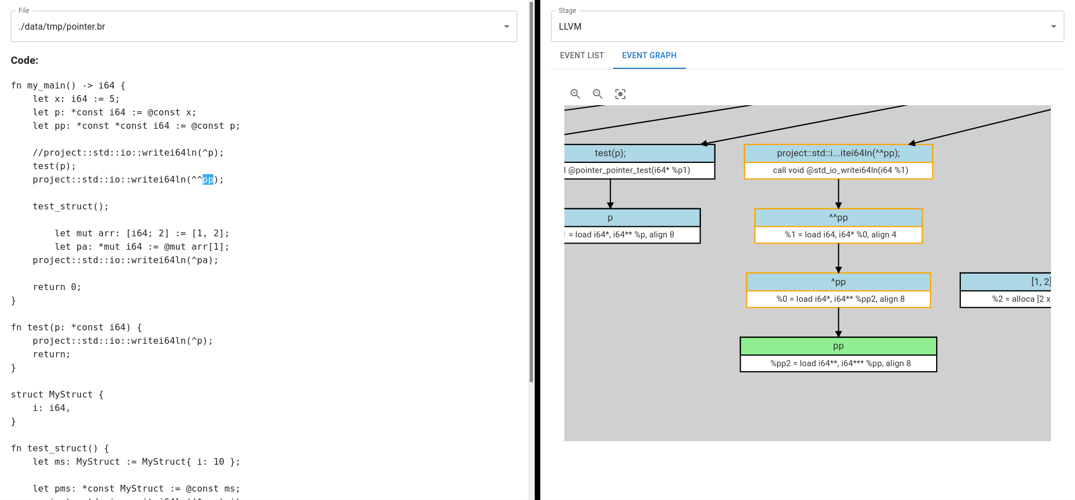
And here’s a beakdown of how the same expression was transpiled into LLVM:
-
And a different view showing the LLVM IR for the selected function:
4 - Concepts
Guiding ideas for Bramble and Thorn
Design principles which are guiding the development of Bramble and Thorn.
4.1 - Projects
How projects work in Bramble.
How projects work in Bramble.
Projects
A project can be either a single Bramble source code file or
a directory containing one or more Bramble files.
To compile a single file, pass the pass to the file itself to
the compiler. To compile a multi-file project, pass the path
to the projects root directory to the compiler.
Importing a Project
To import an external Bramble project into your project you
will need to manifest and the binary of the import target
project.
Referring to Imported Items
To use an imported item in your project, you will have to use
the canonical path to the item. This path is specified with
project::<project name>[::<sub directory>]*::<file>[::<module>]*::<item>
Allowing use statements to create aliases and remove the need for
full paths to imported items is a QOL feature that has not yet been
added to Bramble.
Manifests
If you want to use a project as a library in another project,
you need to generate a project manifest. This manifest is a
file which includes information about exported functions and
types.
To generate a manifest, pass the --manifest flag to the
compiler.
Importing
The manifest is then passed to the compiler so that the compiler
will add the items from the other project to your current
project as external imports.
Linking
Bramble currently uses gcc to perform linking. This is the
final step for handling imports. You will need to pass the
binary for your project and the binary for the imported project
to gcc and it will output the final executable file.
Note: that only one binary can include a main function.
Examples
There are two examples of multi-file projects in the Bramble
integration test suite: ./tests/src/projects/basic and
./tests/src/projects/nested.
All integration tests import the std::io project and
the ./tests/make.sh script shows how to build a project with
imports.
4.2 - Modules & Paths
Using Modules to Organize Code
Using Modules to Organize Code
Modules
A module is a purely organizational structure in Bramble. They allow
you to group related functions and types together under a shared
name.
Accessibility
The concepts of public and private and accessibility are not yet
implemented in Bramble.
Default Modules
In Bramble, there are a few default modules that always exist and
help to organize your code.
- The
project module. This is the parent module and corresponds to your
project as a whole. There is only one project module in any given
project. The project module is also what you import when you import
another Bramble project into your code.
- The
file module. The file module is a module that represents a
source code file and it has a name that is the same as the file name.
directory modules. If there are subdirectories in your project,
those will be added as modules which contain all the times in
those subdirectories.
Custom Modules
Within your own code, you can use mod to create modules that fall
under the file module.
Using Paths
There are two types of paths in Bramble: relative and canonical.
The relative path is a path that gives directions to an item
starting from the current module, this path is dependent upon
where it is used. The canonical path starts from the project
root. This path will always point to the same item no matter
where in the source code it is used.
Path Keywords
There are several path keywords.
project: all canonical paths begin with the project keyword.self: self is an alias for the current module.super: move to the current modules parent module.
Example
Here is an example of a module with another module in it:
mod my_mod {
fn is_3(i: i64) -> bool {
let x: i64 := self::inner::add(1, 2);
return i == x;
}
fn plus(a: i64, b: i64) -> i64 {
return a + b;
}
mod inner {
fn add(a: i64, b: i64) -> i64 {
return super::plus(a, b);
}
}
}
If this source code were contained in the project: example in the
file foo.br, then the project module is example and the file
module is foo. The canonical path to add is
project::example::foo::my_mod::inner::add.
In this example, self::inner::add and super::plus represent
relative paths.
4.3 - Types
Basics of Bramble Types
Primitives
| Keyword |
Description |
| bool |
boolean |
| i8 |
signed 8 bit integer |
| i16 |
signed 16 bit integer |
| i32 |
signed 32 bit integer |
| i64 |
signed 64 bit integer |
| u8 |
unsigned 8 bit integer |
| u16 |
unsigned 16 bit integer |
| u32 |
unsigned 32 bit integer |
| u64 |
unsigned 32 bit integer |
| f64 |
64 bit float |
| string |
C Style String |
| null |
A special type that corresponds to the null keyword. It represents a pointer that is not pointing to any address. |
Arrays
Bramble supports staticly sized arrays of any type. The syntax
for an array type is [<type>; <size>]. For example, [i32; 4]
creates an array of 4 i32 values. Getting an element in array is
done via the [] operators. For example, arr[0] will return the
0th element of the array arr.
Example:
let arr: [i64; 2] := [0, 1];
let x: i32 := arr[0];
Structures
A structure is a named aggregate type consisting of 0 or more named
fields, where each field as a type. Fields can be primtive, arrays, or
structures.
struct MyStruct {
field: i32,
foo: AnotherStruct,
barr: [i8; 5],
}
To access a field in the structure, use the access operator: foo.bar.
For an array of structures you would use arr[0].bar. For a structure
in a structure: foo.bar.fizz.
Raw Pointers
Like most modern languages, Bramble will have a safe system for
handling references, but to build that system and to support FFI
a form of raw pointers is necessary. Raw pointers simply represent
and address to a location in memory and offer no safe guards.
There are two types of raw pointers:
| Keyword |
Description |
| *const T |
Raw pointer to an immutable location in memory |
| *mut T |
Raw pointer to a mutable location in memory |
A raw pointer can be created for any type in the langauge, including
structures and arrays.
Creating a Raw Pointer
@const x will create a raw pointer to any variable x. If x has type
T then @const x will have type *const T. x can be immutable or
mutable.
@mut x will create a raw pointer to a mutable location x. x must
be mutable.
let mut x: i32 := 5;
let cp: *const i32 := @const x; // Create a raw pointer to an immutable location
let p: *mut i32 := @mut x; // Create a raw pointer to a mutable location
The following would fail, because x is immutable:
let x: i32 := 5;
let p: *mut i32 := @mut x; // Error: cannot make a mutable pointer to immutable variable
Dereferencing a Raw Pointer
The ^ operator dereferences raw pointers.
Mutable raw pointers can be used on the left side of mutations:
let mut x: i32 := 5;
let p: *mut i32 := @mut x;
mut ^p := ^p * 2; // This will change the value stored in the location `x`
Unsafe Blocks
In the future, Bramble will require the use of raw pointers to be contained
within unsafe blocks, as is standard for many languages.
4.4 - Thorn Protocol
The interface between Bramble and Thorn.
How Bramble communicates insight information to the Thorn insights
platform.
Insights
The Thorn insights platform provides a first-class feature to give
developers complete insight into everything Bramble does during compilation
and why.
In order for Bramble to communicate with Thorn there is a communication
protocol that defines how Bramble records every decision it makes. This
is a set of JSON files that Bramble will generate when insight tracing
is turned on.
Generating Insights
To generate the Thorn insights data, use the --json-trace flag on
the Bramble compiler.
Thorn Protocol
Spans
The core value in the Thorn protocol is the span. This is a tuple that
uniquely identifies a span of code in your project. Spans are unique across
all the files in your project.
Source Map
In order to make sure that every file in your project can be assigned unique
spans, each file must be assigned a span range from the global span space.
Every span within a specific file will be contained within it’s span range in
the Source Map file.
In theory, spans can cross files, but there are currently no cases where that
would happen.
Example Source Map:
[
{
"source": "./main.br",
"span": [0, 264]
},
{
"source": "./second.br",
"span": [264, 401]
}
]
Trace File
The events themselves are recorded to trace.json. This file stores the trace
of your source code through every stage of the compiler. It is consists of
an array of compiler events. The compiler events represent decisions the compiler
makes about different spans of your code. Each event consists of the span that
caused the decision, the compiler stage, and information about the decision that
was made.
Every event is given a unique integer ID. Some events have a parent ID, this means that
the parent event triggered this event.
Event Results
Currently, an event can have one of two results: ok or err. Both of which have
string values. ok means that the compiler successfully made a decision. err means
that the compiler failed to make a decision and includes the error message detailing
why the compiler failed.
Ref Spans
Some stages of compilation require context (for example, type resolution has to
look up the declarations of functions). When a compiler decision needs to refer
to another part of your code to make a decision, that reference is recorded with
a ref span, which records the secondary span of your code that the compiler
referred to.
Example Trace File
[{"id": 428, "parent_id": 427, "stage": "parser", "source": [393, 398], "ok": "Boolean Negate"},
{"id": 427, "parent_id": 426, "stage": "parser", "source": [393, 398]},
{"id": 426, "parent_id": 425, "stage": "parser", "source": [393, 398]},
{"id": 425, "parent_id": 424, "stage": "parser", "source": [393, 398]},
{"id": 424, "parent_id": 423, "stage": "parser", "source": [393, 398]},
{"id": 423, "parent_id": 422, "stage": "parser", "source": [393, 398]},
{"id": 422, "parent_id": 401, "stage": "parser", "source": [386, 398], "ok": "Return"},
{"id": 401, "parent_id": 321, "stage": "parser", "source": [353, 401], "ok": "Funtion Definition"},
{"id": 321, "stage": "parser", "source": [264, 401], "ok": "File Module"},
{"id": 437, "stage": "canonize-item-path", "source": [0, 401], "ok": "$basic::basic"},
{"id": 438, "stage": "canonize-item-path", "source": [0, 264], "ok": "$basic::main::main"},
{"id": 439, "stage": "canonize-item-path", "source": [0, 231], "ok": "$basic::main::my_main"},
{"id": 440, "stage": "canonize-item-path", "source": [233, 264], "ok": "$basic::main::MyStruct"},
{"id": 441, "stage": "canonize-item-path", "source": [255, 261], "ok": "$basic::main::f"},
{"id": 442, "stage": "canonize-item-path", "source": [264, 401], "ok": "$basic::second::second"},
{"id": 443, "stage": "canonize-item-path", "source": [264, 351], "ok": "$basic::second::my_bool"},
{"id": 444, "stage": "canonize-item-path", "source": [353, 401], "ok": "$basic::second::notter"},
{"id": 445, "stage": "canonize-item-path", "source": [363, 370], "ok": "$basic::second::b"},
{"id": 446, "stage": "canonize-type-ref", "source": [75, 89], "ok": "$basic::main::MyStruct"},
{"id": 447, "stage": "canonize-type-ref", "source": [153, 176], "ok": "$basic::second::my_bool"},
{"id": 448, "stage": "canonize-type-ref", "source": [305, 317], "ok": "$basic::second::notter"},
{"id": 449, "stage": "canonize-type-ref", "source": [321, 334], "ok": "$basic::second::notter"},
{"id": 453, "parent_id": 452, "stage": "type-resolver", "source": [39, 40], "ok": "i64"},
{"id": 455, "parent_id": 454, "stage": "type-resolver", "source": [44, 45], "ok": "i64"},
{"id": 454, "parent_id": 452, "stage": "type-resolver", "source": [43, 45], "ok": "i64"},
{"id": 452, "parent_id": 451, "stage": "type-resolver", "source": [39, 45], "ok": "i64"},
{"id": 451, "parent_id": 450, "stage": "type-resolver", "source": [26, 46], "ok": "i64"},
{"id": 459, "parent_id": 458, "stage": "type-resolver", "source": [87, 88], "ok": "i64"},
{"id": 458, "parent_id": 457, "stage": "type-resolver", "source": [75, 89], "ok": "$basic::main::MyStruct", "ref": [233, 264]}]
4.5 - Raw Pointers
How Bramble represents memory addresses, pointers to locations in memory, and the manipulation of memory directly.
How Bramble represents memory addresses, pointers to locations in memory,
and the manipulation of memory directly.
Overview
In order to support low level memory operations and full FFI, Bramble must
have the ability to operate on memory directly through pointers and
pointer manipulation. As with many modern languages, Bramble wants users
to avoid using these tools, except in the cases where they are the only
or clearly correct option. To this end, the operations to get raw pointers
are tedious and typing heavy and will, eventually, have to happen within
an unsafe expression block.
Pointer Types
There are two raw pointer types: *const T and *mut T. *const T
is a pointer to an immutable location in memory: dereferencing
this pointer will let you read from this location in memory but it will
not let you write to this location. *mut T is a pointer to
a mutable location in memory: dereferencing this pointer will let you
read from this location and write to this location.
Creating a Pointer
To create a pointer, use the address of operators: @const or @mut.
@const will return a *const pointer to the operand.
@mut will return a *const pointer to the operand, but it can only
be applied to mutable values.
The operand of @const and @mut must be an addressable expression.
This is an expression that resolves to a value that has a location in
memory, generally this is a variable.
Dereferencing a Pointer
To read from or write to the location through a raw pointer, you need
to use the dereference operator: ^. To read from a memory location
you can use the ^pointer in any expression where the underyling
type would be valid. To write to a memory location, use mut ^p := ....
Pointer Arithmetic
To get addresses that are offsets from a given pointer, use the @
in its binary form: p@-2 will return a new address which is
equivalent to p - 2 * (size_of(T)) where T is the type of the
value that p points to.
5 - Standard Library
The Standard Library
5.1 - std::io
Input & Output Functions
A list of all the functions in the std::io module.
This is a standard library containing support functions for handling some basic IO
operations.
All functions in std::io have a canonical path that starts with project::std::io::<function>.
For example: project::std::io::write("Hello World\n").
Functions
| Function |
Description |
readi64 |
Reads a single i64 from stdin |
write |
Writes a string to stdout |
writeln |
Same as write but appends a newline character |
writebool |
Writes a bool to stdout. This will write either true or false |
writeboolln |
Writes a bool to stdout and moves to a newline. This will write either true or false. |
writef64 |
Writes an f32 to stdout |
writef64ln |
Writes an f32 to stdout and moves to a newline |
writei8 |
Writes an i8 to stdout |
writei16 |
Writes an i16 to stdout |
writei32 |
Writes an i32 to stdout |
writei64 |
Writes an i32 to stdout |
writeu8 |
Writes an u8 to stdout |
writeu16 |
Writes an u16 to stdout |
writeu32 |
Writes an u32 to stdout |
writeu64 |
Writes an u64 to stdout |
writei8ln |
Writes an i8 to stdout and moves to a newline |
writei16ln |
Writes an i16 to stdout and moves to a newline |
writei32ln |
Writes an i32 to stdout and moves to a newline |
writei64ln |
Writes an i64 to stdout and moves to a newline |
writeu8ln |
Writes a u8 to stdout and moves to a newline |
writeu16ln |
Writes a u16 to stdout and moves to a newline |
writeu32ln |
Writes a u32 to stdout and moves to a newline |
writeu64ln |
Writes a u64 to stdout and moves to a newline |
6 - Bramble Reference
Reference documentation for the Bramble Language and the Compiler
This provides reference documentation for the Bramble language and
for the compiler.
Within this section will be clear and explicit documentation covering
the features of the Bramble language, including syntax rules, semantic
rules, and so on.
6.1 - Keywords
Bramble Language Keywords
Operators
| Name |
Description |
null |
Represents a null reference or address. A reference that does not point to any location in memory |
null
null represents a raw pointer value that does not point to any location in memory.
This is used to initialize a raw pointer with a placeholder value,
when it is not yet known where the pointer should point.
null is also used to check if a pointer points to a valid location
in memory or not. For managing heap allocated memory, null can
be used to check if memory has been allocated on the heap or not.
null can be used for initialization, mutation, or comparison
operators, but not for any other operation.
6.2 - Operators
Bramble Operators
Operators
| Operator |
Description |
^ |
Dereference raw pointer |
==, != |
Equal to and Not Equal to |
<, <=, >, >= |
Comparison operators |
@const |
Address Of immutable addressable expression |
@mut |
Address Of mutable addressable expression |
@ |
Raw pointer offset |
== & !=
Equality Operations
== checks if the value on the left and the value on the right are equal.
!= checks if the value on the left and the value on the right are not equal.
For raw pointers, this compares the memory addresses stored in the
pointers rather than the values stored at the memory address.
Syntax
EQUAL := EXPRESSION == EXPRESSION
NOT_EQUAL := EXPRESSION != EXPRESSION
Semantics
x, y: T, T: Primitive :- x == y -> bool
x, y: T, T: Primitive :- x != y -> bool
<, <=, >, & >=
Comparison Operations
These are the ordering operations and compare two values to see what
relative order they are too each other.
For raw pointers, these compare the memory addresses stored in the
pointer rather than the values stored at the memory address.
Syntax
LT := EXPRESSION < EXPRESSION
LTE := EXPRESSION <= EXPRESSION
GT := EXPRESSION > EXPRESSION
GTE := EXPRESSION >= EXPRESSION
Semantics
x, y: T, T: Primitive :- x < y -> bool
x, y: T, T: Primitive :- x <= y -> bool
x, y: T, T: Primitive :- x > y -> bool
x, y: T, T: Primitive :- x >= y -> bool
@const & @mut
Raw Pointer Creation
The Address Of operators return a raw pointer to the location in memory
where the value of the operand is stored. The operand for @const
and @mut must be an addressable expression.
An addressable expression is any expression which is logically tied
to a location in memory and is not a temporary variable used for
transferring data between calls. An example of an addressable expression
is a named variable, or the element of an array which is bound to a
variable. An addressable expression may be stored in the stack or
in the heap.
An example of a non-addressable expression, which may have a location
in memory is the temporary value of a structure expression:
MyStruct{ x: 1, y: 2, z: 3}.
This may be allocated to the stack to because it is too big to fit in
a register, but that location is considered strictly temporary and may get
used for later structure expressions, or, for small structures, be optimized
into a physical register or integer literal. Therefore, there can be no
guarantee that it can be safely addressed and it is considered non-addressable.
Note about Mutability
It’s important to remember that there are two different concepts of
mutability for a value of type pointer. The first, and most important,
is the mut in *mut T: this means that the location the pointer points
to can be mutated through the pointer. The second is the mut that
refers to a variable of type *(const|mut) T (let mut p: *const i64 ...),
this means that the pointer variable can be mutated (not the location it points to);
in other words, that the pointer can be changed to point do a different address.
Example
let i: i64 := 10;
let mut pi: *const i64 := @const i;
let mut j: i64 := 15;
let pj: *mut i64 := @mut j;
mut pi := @const j; // Here, `pi` is mutated to point to `j`.
// Note, that it still _cannot_ be used to mutate `j`
Syntax Rules
ADDRESS_OF := @(const|mut) EXPRESSION
The @ operator must be followed by either const or mut. This indicates
whether to pointer can be used to write to the memory location or only
to read from the memory location.
Semantic Rules
// x is an addressable value, T is a type
x: T :- @const x -> *const T
mut x: T :- @const x -> *const T, @mut x -> *mut T
@const can take any addressable value, whether it is mutable or immutable
and will always return a value of *const T, where T is the type of the
operand.
@mut can only be applied to an addressable value that is declared as mutable.
And will return a value of type *mut T, where T is the type of the operand.
This pointer can be used to write to the memory location as well as read from
the memory location.
^
Raw Pointer Dereference operator
Taking a *const T or *mut T value as an operand, the ^ operator accesses
the value stored in the location pointed to by the operand.
If the location is mutable (operand is of type *mut T), then the
dereference expression can be used on the left of a mutation expression.
If T is an array or a structure, then the result of the dereference
operation can be used as the left of element access or field access operators.
Example
// Dereference a primitive value
let i: i64 := 5;
let p: *const i64 := @const i;
project::std::io::writei64ln(^p); // Prints 5
// Using the dereference in a mutation expression
let mut j: i64 := 10;
let pj: *mut i64 := @mut j;
mut ^pj := ^pj + 1; // Adds 1 to j
// Using with an array
let arr: [i32; 2] := [1i32, 2i32];
let p: *const [i32; 2] := @const arr;
^p[0]; // Will resolve to 1i32
Syntax Rules
DEREFERENCE := ^EXPRESSION
Semantic Rules
x: *const T :- ^x -> T
x: *mut T :- ^x -> mut T
Raw Pointer Offset
The @ operator is a binary operator and is used for computing address
offsets from a raw pointer value. Given a pointer to a memory location,
you can use @ to move to the left or the right of that memory location.
The offsets are computed in increments of the size of the underlying type.
So, if p is pointer to an i64, then p@1 would increment the address
by 1*size_of(i64) or 8 bytes and p@-3 would decrement the address by
-3*size_of(i64) or -24 bytes.
The left operand must be of type *(const|mut) T and the resulting type
will be the same as the left operand. The right operand must be an integer
type (either signed or unsigned).
Example:
let mut arr: [i64; 3] := [1, 2, 3];
let mut p: *const i64 := @const arr[1];
project::std::io::writei64ln(^(p@-1)); // Will print 1
let p2: *const i64 := p@1;
project::std::io::writei64ln(^p2); // Will print 3
Syntax Rules
RAW_POINTER_OFFSET := EXPRESSION @ EXPRESSION
Semantic Rules
x: *const T, o: i8|i16|i32|i64|u8|u16|u32|u64 :- x@o -> *const T
x: *mut T, o: i8|i16|i32|i64|u8|u16|u32|u64 :- x@o -> *mut T
6.3 - Type Casting
Type Casting
Operator
| Name |
Description |
as |
Allows primitive types to be cast between each other. |
Casting
The as operator converts a value of one type to a value of another type.
As much as possible, the actual value is preserved, but there are certain
value ranges for which that cannot be done.
This can also be used to change the target type of a Raw Pointer
value. For example, *const MyStruct can be changed to *const u8.
Valid Casts
| Expression |
Target Type |
Description |
| Numerical |
Numerical |
Signed integers, unsigned integers, and floating point numbers can be cast between each other. |
*mut T |
*const Y or *mut Y |
Mutable raw pointers can be cast to constant or mutable raw pointers |
*mut T or *const T |
*const Y |
Any raw pointer can be cast to a constant raw pointer |
*mut T or *const T |
integer |
Any raw pointer can be cast to an integer |
| Integer |
*const T |
An integer can be cast to a constant raw pointer |
Numerical types: bool i8 i16 i32 i64 u8 u16 u32 u64 f64
Integer types: bool i8 i16 i32 i64 u8 u16 u32 u64
Floating point types: f64
T and Y can be any type.
For raw pointer casts, the goal is to make it as difficult as possible
to bypass the declared mutability of a location in memory.
Integer Upcasting
When an integer is cast to an integer with higher bit width the additional
bits need to be filled. If the source expression operand is signed, then
the upcast will extend the sign bit. If the source expression operand is
unsigned, then the upcast will do a zero extend.
Examples
| Expression |
Result |
Description |
1i8 as i32 |
1 |
Upcasting from signed to signed will result in the same value. |
-1i8 as i32 |
-1 |
The negative sign is extended resulting in the same value. |
-2i8 as u64 |
18446744073709551614 |
When upcasting a signed integer, the sign is extended. |
65535u16 as i64 |
65535 |
Unsigned integers are upcast by extending zeroes. |
Integer Downcasting
When an integer is cast to a type with a smaller bit width, then the extra
bits in the source are truncated.
Examples
| Expression |
Result |
Description |
-2i16 as i8 |
-2 |
These values are small enough that truncation has no effect. |
-5i16 as u8 |
254 |
u8 is formed by truncating all but the least significant byte from -5. |
-500i16 as i8 |
12 |
Truncation converts the negative i16 to a positive i8. |
Floating Point to Integer Casting
FP to Int conversion takes the FP value and converts it to an integer value. If
the FP value is outside the possible bounds of the target Integer type, then the result
is a poison value. Conversion is always done by rounding towards zero.
For more details on poison values, see the LLVM Documentation.
Syntax Rules
EXPR as TYPE
Semantic Rules
S, T: Primitive Type, e: S :- e as T -> T
7 - Contribution Guidelines
How to contribute to Bramble and Thorn
Any contribution to the Bramble language is welcome.
Bramble is developed in the Rust programming language and is built on top of LLVM for
its backend. If you wish to contribute, feel free to reach out through one of the
contact options or download the repository from GitHub and play around with the
language.
The Thorn Insight tools are developed with Rust and React (for any GUI tools).
Language Proposals
If you have any proposals for the language, add them as Enhancement issues on the
GitHub repository. Include a brief description of what problem the proposal would
solve and any examples or diagrams you believe necessary to help explain your idea.
Code Review
All submissions will require a code review. To submit a PR, please document the changes that
were made, why they were made (with a link to an issue if one exists), along with a brief
outline of how the changes were tested.
Tests
Bramble is always striving to be as thoroughly tested as possible, so please make sure
to add or update any necessary tests for you changes. For any changes to the language
or to LLVM output, make especially sure to check the integration test suite.
8 - RFCs
Current and past design documents for features in Bramble and Thorn.
These documents provide in-depth details to the design process for major
features added to Bramble and to Thorn.
The numbers used to identify RFCs correspond to the GitHub issue number
used to track the feature. Which is why they they may be very large and
show gaps between numbers.
8.1 - RFC 248 - Raw Pointers
How to represent raw pointers in Bramble
Design for Representing Addresses in Bramble
Note: I have used my rough understanding of how to state type rules in order
to express the semantic rules for raw pointers. There may be mistakes in my
statements due to lack of experience.
Problem
Within the Bramble language there is no representation of address based operations
or pointers. This severely limits both what can be built with Bramble and
the FFIs that Bramble can call. In order for Bramble to grow, there needs to be
a representation of the most basic raw pointer concepts. These can then
be used to build not only heap based allocations, but smart pointers, or
garbage collectors, etc.
Goal
In this document is the design for how raw pointers will be represented
in the Bramble language.
UX
Being danger, the use of raw pointers should be both discouraged except in special
cases (features which require raw pointers, FFI uses, and performance) and it
should be immediately obvious to a reader that a raw pointer is being used.
And the syntax of raw pointers should reflect this discouragement for writers
and make raw pointer use obvious for readers.
So, any use of raw pointers should be obviously different from safer uses of
reference values (e.g. Rust borrows, smart pointers, garbage collected pointers, etc).
This leads to several design goals:
- Raw pointer types should be as explicit as possible when written down.
- Creating a raw pointer directly to a variable should be obviously different.
(e.g. Rust uses the addr_of
macro to just get the address and bypass any safety checks).
- Dereferences should also be obvious and explicit. Where dereferences of
smarter reference types might be implicitly injected by the compiler, for raw
pointers they must all be explicitly written.
This document lays out the language features for supporting raw pointers
themselves. After this feature is implemented, then the next step is to
implement something like unsafe blocks in C# and Rust to further push
raw pointers to something that a user must “buy into” and to make them
obvious to a reader.
Requirements
- Immutability must be respected as far as it can possibly be guaranteed. It
is impossible to guarantee it is respected on the other side of an FFI but
within Bramble, if a variable is aquired as immutable then it is a compiler error
for Bramble to ever allow it to be mutated.
- A raw pointer can be assigned either the address of a declared variable or
the
null value. It cannot be assigned an arbitrary integer.
null is a keyword that can be assigned to or compared with all ref types.- It is possible to get the address of any variable, no matter it’s type.
- Function pointers are not covered in this document
- The design should discourage their use to only when necessary.
- Raw pointers can be used on uninitialized memory. (Currently, Bramble does not
allow for uninitialized variables but that will come in the future.)
- When a raw pointer is copied it’s value will be copied and there will now be
at least two extant raw pointers to a location in memory.
- You can get the address of a field in a structure.
- with Raw pointers, you can have internal references: that is a field in
a struct is a pointer to another field in the same struct.
- Comparisons compare addresses. Raw pointers are equal if and only if they
point to the same location in memory or they are both
null.
- There is a way to compute offsets from a raw pointer.
- There is a function for getting the size of a type. This is needed for custom
memory allocation, computing offsets, etc.
- Comparison operators work on raw pointers. (
<, >, <=, >=, ==, !=)
Design
Syntax
There are two parts to implementing raw pointers: the reference types, which
describe variables that hold addresses, and the operators used to to create
and use raw pointers.
Pointer Type
The type syntax is inspired from Rust:
Raw Pointer = *(const|mut) TYPE
Where Type is any primitive or valid custom type, including raw pointers.
const and mut must be specified to help make raw pointers as explicit
as possible and to discourage their use by making them tedious.
Reference Operators
There are two operators that are needed: one to get the reference and one
to dereference a pointer so that a user can access the target variable.
REFERENCE = @(const|mut) (IDENTIFIER[.FIELDNAME]*)
DEREFERENCE = ^EXPRESSION
MUTATE = mut LVALUE := EXPRESSION
LVALUE = [^]IDENTIFIER // The formal labelling of the LVALUE is new to Bramble
Note: currently braid does not support mutations of fields in a struct. This proposal
optimistically hopes that that language change can be fit in here. The LVALUE in Bramble
needs to be greatly matured so it can support derefs, fields, array elements, and
parens to control order of operations. The LVALUE presented here is still not complete
but fully realizing it is outside the scope of this RFC.
The Reference and Dereference operators are unary operators with precedence
higher than member access or array access operators.
The Reference operator can only be applied to identifiers or the fields of an
identifier that’s a structure as those are the
only constructs in Bramble that have physical locations in the computer. Literals,
for example, have a location in the machine code data section but are not
conceptually something that can be referenced. The reference operator explicitly
requires const and mut so that it mirrors the syntax of the raw pointer
type names.
@ is chosen as the addressing
operator rather than the traditional & to make & available for future use
with safer reference/borrowing systems. In C/C++ the & is used to get
the address of a variable. In Rust & is used for both borrowing
and raw pointers (in Rust the & is cast to a raw pointer and a separate
macro must be used to explicitly get the address). For Bramble, I want all interactions
with raw addresses/pointers to be as explicit and obvious as possible so the
addresses are gotten with @. Then & will be used for safe references which
will be what users are encouraged to use.
The @ operator can only be applied to lvalues (identifier or a specific field).
This is because the raw pointer logically refers to a specific location in memory
and all locations in memory are refered to via identifiers. This mirrors the
syntactic rules of C, and is carried into Bramble both because it maps well to the
core philosophies of Bramble and because it provides a very strict rule which makes
implementation easier.
The Dereference operator is ^, which differs from other languages which use
* to dereference pointers. This was chosen to to make the dereferencing of
a raw pointer explicitly different from dereferencing safer references or
smart pointers. The ^ will probably be used for bitwise xor when that operator
is added to Bramble but I believe it will be clear which operator is being used
by whether it is unary or binary.
Unlike the reference operator, the dereference operator can, syntactically, be
applied to any expression. The requirement being that the expression resolve to
a reference type. This is because dereferencing is operating on a value (the
address) and the address is expected to have already come from a variable.
This makes using dereferenced identifiers legal as the left value in mutation
statement.
Both the reference and dereference operator symbols were chosen to be uniquely
applicable to raw pointers and distinct from future, safer, methods of handling
references in Bramble (be those GC pointers, reference counters, or a lifetime system
a la Rust). The priority here is given to clarity for the reader of code rather
than efficiency for the writer.
Operator Precedence
@ and ^ will have the same precedence as unary minus (-) and not (!)
Semantics
Some notes, currently the following types and their uses are semantically legal:
x: i32, y: i32
1. *const *const i32
2. *mut *mut i32
3. ptr: *const *mut i32 :- mut ^^ptr := 5
4. *mut *const i32 :- mut ^ptr := @y
The latter two may seem unintuitive or that they should be illegal.
Example 3 is legal because the outer *const refers to the location in
memory that is storing the *mut i32, that pointer cannot be changed
through indirect means, but because that pointer is an indirect mutable
pointer, the location it points to (the i32) can be changed. Example 4
is legal, because the location that the outer pointer points to is mutable
(it can be changed to point to a different i32) but the i32 that the
inner pointer points to cannot be mutated.
It may make more sense to semantically have an occurance of a *const in
a chain of nested pointers to override and turn the entire chain into
*const.
Reference Operator
The reference operator can only be applied to an Identifier that is a variable
in the current scope. The type of the reference expression is *const T where
T is the type of the variable.
The mutable reference operator @mut can only be applied to a variable that
is also mutable. The type of the mutable reference expression is *mut T.
mut and const are modifiers on the * reference type.
Deference Operator
T: Is a Type :- R: *(const|mut) T
-----------------------
:- ^R -> T
Mutating a dereference:
If the raw pointer is to a mutable location (*mut T) then the value of that
location can be mutated via the dereference operator;
let x: i64 := 1;
let mptr: *mut i64 := @mut x;
mut ^mptr := 5;
The type rules are:
mut ^R := V => T: Type :- R: *mut T, V: T
Dereferencing null or a variable whose value is null is undefined behavior.
Assignment Semantics
A variable of type *const T can be assigned a value of type *const T or
a value of *mut T.
A variable of type *mut T can only be assigned a value of type *mut T.
let x: i64 := 5;
let mut y: i64 := 10;
let cptr_x: *const i64 := @const x; // Legal
let cptr_y: *const i64 := @const y; // Legal
let mptr_x: *mut i64 := @mut x; // Illegal, cannot get mutable address to an immutable variable
let mptr_y: *mut i64 := @mut y; // Legal
let mptr_x: *mut i64 := @const x; // Illegal, cannot get mutable address to an immutable variable
let mptr_y: *mut i64 := @const y; // Illegal, cannot cast a const location to a mutable pointer
Ref Type Variable Mutability
A variable of reference type (immutable and immutable) can itself be annotated
as mutable: this means that the address stored in the variable can be mutated
it has no bearing on if the location the address refers to can be mutated.
let x: i64 := 5;
let x2: i64 := 5;
let mut y: i64 := 10;
let mut y2: i64 := 10;
let mut cptr_x: *const := @const x;
let mut cptr_y: *mut := @mut y;
mut cptr_x := @const x2; // Legal
mut cptr_y := @mut y2; // Legal
Copying References
Copying: a mutable reference can be copied to a variable of type *const or
*mut, so long as the underlying type is the same. An immutable reference
can only be copied toa variable of type *const.
Examples:
fn write_to(m: *mut i64) {...};
fn read_from(i: *const i64) {...};
let x: i64 := 5;
let mut y: i64 := 10;
let cptr_x: *const i64 := @const x; // Legal
let cptr_y: *const i64 := @const y; // Legal
let cptr_x2: *const i64 := cptr_x; // Legal
let cptr_y2: *const i64 := cptr_y; // Legal
let mptr_y: *mut i64 := @mut y; // Legal
let mptr_x: *mut i64 := @mut x; // Illegal, cannot get mutable address to an immutable variable
let mptr_x: *mut i64 := cptr_x; // Illegal, cannot get mutable address to an immutable variable
write_to(@mut y); // Legal
write_to(@const y); // Illegal, type mismatch requires *mut i64 but `@x` has type *const i64
write_to(@mut x); // Illegal, @mut cannot be applied to an immutable variable
read_from(cptr_x); // Legal
read_from(cptr_y); // Legal
read_from(mptr_y); // Legal
read_from(@const x); // Legal
read_from(@const y); // Legal
read_from(@mut y); // Legal
Comparisons
Comparisons are done on the addresses stored in the reference variable.
Mutable and immutable references can be compared with each other.
Equality
== - returns true if the LHS and RHS have the same address value, otherwise false.!= - returns true if the LHS and RHS have different address value, otherwise false.
Less Than/Greater Than
Comparison operators will operate on the numerical values of the addresses as if they
were integer types.
Offsets
A key part of raw pointers is being able to use them to move through large
blocks of allocated memory: e.g. dynamic arrays and so on. On a semantic level
this mirrors the array access operation [n] with the key difference being that and offset
could be negative.
A similar, but visibly different operator is provided for getting offsets
from a given raw pointer (which addresses the need for pointer arithmetic).
ptr<i64> // The <> operator takes a signed 64 bit integer and returns a new address
The offset operator will get an offset address in terms of multiples of the size
of the underlying type. The address it will return computes as ptr value + size_of(T) * offset
where T is the underlying type of the ptr.
So for a pointer to a i64, the size of the underying type is size_of(i64) = 8
and the offset will move in steps of 8: ptr<2> = ptr + 2 * 8 or
ptr<-3> = ptr - 3 * 8.
The <> characters were chosen to make the pointer offset operation visually
distinct from the array access operation while still sharing some resemblance
because logically they operate in identical manners with the array access being
more restrictive in its inputs (they must be unsigned).
Syntax:
PtrOffset = IDENTIFIER<EXPRESSION>
Semantics:
T: Type :- R: *(const|mut) T
----------------------
p: R, o: i64 :- p<o> -> R // The offset of a *const is *const and the offset of a *mut is *mut
Alternative syntax: Use this as a binary operator: ~ e.g. ptr ~ -5. I don’t
like this because it’s very subtle and with some fonts could be confused with -.
One reason to avoid using <...> is it’s a pain to implement in the parser.
Perhaps $ or # as binary operators. The semantic rules for typing stay the same
but it becomes easier to parse.
Decision
At the time of implementation, I’ve decided to use @ as a binary operator for raw
pointer arithmetic. This is because all the other operators (e.g. <> and # and $)
could have future uses, the @ is already associated with raw pointers, and this
minimizes the amount of special characters which are devoted to raw pointer manipulation.
Member Access on Values of Reference Type
If a reference points to a structure then to access members of the structure you
need to dereference the pointer first: *ptr.field or (*ptr).field. To dereference
a field in a structure that is a reference: *(ptr.field_ptr).field or
(*(ptr.field_ptr)).field.
size_of
The size_of function takes a type and returns the number of bytes allocated to store
a type in memory. This takes into account padding bytes that might be added for
memory alignment purposes.
Syntax:
SIZE_OF = size_of(TYPE)
Type:
:- size_of(T) -> u64
For simplicities sake, this is operating on the C notion of size where every type as a
size. For primitive types with the bitsize in the name, the size of the type shall remain
constant across all versions of Bramble and all platforms and architectures.
Insight
The insight should focus on the physical nature of pointers and addresses, as they
represent the actual locations in memory and deal with interacting with those physical
realizations of the logical variables. So, when possible the visualization and Insight
should emphasize that link to the physical resource.
Recorded events:
When the @ operator is applied to a variable then:
- The lexer will emit an event for the
@ token
- The parser will emit an event for generating a
@ unary node in the AST.
- The type resolver will emit an event which includes a reference span to the definition
for whatever is the operand of
@, because the declaration of that variable
is also the aquisition of the physical memory.
- If the operand is a field of a structure, then it will reference the declaration of
that structure variable.
- The reference type should probably be annotated to make it explicit that this
is refering to the same physical location and not that it is using a reference for
a compile time decision.
- LLVM will emit an event with the
LLVM get address instruction.
- Record if the pointer is pointing to a type which is memory aligned
- When a pointer is bound to a Field in a struct, the node should display the
field name. Have a reference to the span for the field’s definition.
When the * deref instruction is applied to an expression:
- The lexer will emit an event for the
* token.
- The parser will emit an event for generating the
* unary node in the AST.
- The type resolver will emit an event which includes a reference to
the definition of where the operand comes from.
This is a bit outside the scope of this RFC, but because this is dealing with
language features that surface the physical nature of how variables are stored:
It would be nice to record the memory layout information for all structs and
display that in the LLVM tab for the Viewer.
It would also be nice to have a compiler flag to print out memory layout table
for all types after compilation.
Viewer
Highlight the creation of raw pointers and the dereference of raw pointers in some
manner to emphasize that something dangers is being done.
In this case, the Cell of an @ expression or a * expression will be will be colored
a light orange as a warning sign.
Tests
Integration Tests
- Get Reference to each primitive type
- Get Reference to array
- Get Reference to structure
- Get reference to field in structure
- Get reference to element in array
- Get reference to reference
- Repeat all tests for mutable references
- Test passing a reference to a function
- Test passing a mutable reference to a function and function mutates value
- Return reference from function
- Test using malloc and free
- Copy struture with reference field => both copies point to the same value
- Test derefence of each of the Reference tests
- Test mutable dereference of each of the reference tests
- Reference to a mutable value, mutate the value, test that the reference
reflects the mutation.
- test initializiing a reference to null
- Test comparing a reference to a null
- Test comparing two references compares addresses
- Get pointer to first element in the array, then use pointer arithmetic
to move to each element of the array.
Implementation
Types
The const keyword will be added to the token set and the lexer.
A new Ref variant will be added to the Type enumeration. The
Ref variant will have two fields. One field is_mutable boolean which is
false for immutable references and true for mutable references. And a boxed value
to the target type that the reference refers to.
The Parser will be updated to parse the ref type annotations according to this
grammatical rule:
RefType = *(const|mut) <Type>
*const <Type> will set is_mutable to false and the target type to <Type>.
*mut <Type> will set is_mutable to true and the target type to <Type>.
@ Operator
@ will be added to the Lexer and token set as Ampersand.
Two new variants will be added to the Expression enumeration: AddressOf and
AddressOfMut.
The parser will follow these rules:
AddressOf = @<Identifier>
AddressOfMut = @mut <Identifier>
Semantic rules will be added of the form:
- For
AddressOf the operand must be a variable. It can be immutable or mutable.
- For
AddressOfMut the operand must be a mutable variable.
^ Operator
The ^ token already exists in the Lexer and token set.
A new unary rule will be added to the Parser:
Deref = ^EXPRESSION
DeRefAssignment = mut *EXPRESSION := EXPRESSION
A new variant will be added to the Expression enum. This variant will have a single
child, which is the expression it is dereferencing. A new variant for mutations will
be added for mutating a reference.
Semantic Rules will be added of the form
- For DeRefAssignment, the
<Expression> on the LHS must be mutable reference.
- For
*<Expression> in the LHS, the type of <Expression> must be a Reference
type (mutable or immutable). If the type of <Expression> :- *(const|mut) T then
the type of *<Expression> :- T
size_of
The size_of function will be implemented using the LLVM API and computed as a static
value during compile-time.
https://stackoverflow.com/questions/14608250/how-can-i-find-the-size-of-a-type
https://llvm.org/doxygen/classllvm_1_1DataLayout.html#aa48b3b7e554b44f4e513d5dd8d9f9343
Syntactic Fuzzer Changes
- Add type annotations for
*const T and *mut T. This should be able to use the
same logic as arrays.
- Add expression generation for taking the reference of an identifier.
- Get a raw pointer to a field in a structure.
- Add a failure test by generating a reference operator where the operand is not an identifier.
- Add deref generation for expressions.
- Add deref mutation generation for statement generators.
- Compute raw pointer offsets
- Mutate dereference to a field name
8.2 - RFC 257 - Addressable Expressions
How to represent the expressions that can be used on the left hand side of assignments and mutations.
Addressable Expressions
Overview
Allow the Bramble compiler to support more than just identifiers as the
LHS of mutation operations and the operand of @(const|mut) operations.
Specifically, be able to use array elements and structure fields so
that the following would be legal:
mut arr[0] := 5;
mut st.field := -1;
@const arr[0]
@const st.field
mut ^(@mut arr[0]) := 2;
Solution
(The term “Addressable” is inspired by the language used in the Go Lang spec).
The expressions which can be mutated or referenced with @ are expressions
which have places somewhere in memory (the stack or the heap). These
are called Addressable values. Without a place in memory, obviously, the
expression cannot have its value changed or its address taken. Expressions which
evaluate to a value are Value Expressions. All addressable expressions are also
value expressions: in this case their value is read from their place in memory.
Whether an Addressable expression resolves to its address in memory or its value
is context dependent: specifically, the operation and what operand position the
expression takes. For example, the LHS of a mutation operation would resolve to
an address, but the RHS of the same mutation operation would evaluate to an
address.
I propose adding a new is_addressable flag to the SemanticContext of an
expression. This will be added before type resolution. During type resolution,
the compiler will not only check that the types are correct, but will also
check if an operand is addressable for the operations which require addressable
values.
In order to support mutation operations, an is_mutable flag will also have
be added to the SemanticContext. Currently, this flag only exists in the
symbol table for variables, but this cannot support dereference expressions
or field access or array indexing expressions. The is_mutable flag will
remain in the symbol table and a flag will be added to SemanticContext for
mutability of addressable expressions.
The mutability and addressability of an expression will be combined into a single
flag with 4 possible states: None|Value|Addressable|AddressableMutable. An expression
can only be mutable if it is addressable, so having two separate flags creates
risk of accidentally marking a value expression as mutable. None is used
both as a place holder for when an expression has not had it’s Addressability
computed and for nodes which are not expressions (structure defintions, etc).
A new phase ComputeAddressable will traverse the AST and set the addressability
flag for every node in the AST, based upon a set of rules detailed in a following
section.
Then in LLVM Generation, a new method will be added to Expression called
to_addr -> Option<T>, which will return the address of an Addressable
Expression, rather than its stored value, if the expression is addressable
otherwise it will return None. This implementation is easily done by simply
returning the pointer and skipping the build load operation.
Why this design? This design allows for determining whether expressions can be used
for mutations and referencing in a way that is fully independent of the grammar rules
or AST design. Which means both: no major refactoring or changes to the AST and
no added bounds on how the grammar and AST could evolve into the future.
Why have this separate from type resolution? Type resolution is already large
and complex, the danger is that addressability rules checking would get lost
in all the type checking logic. Making it easy to break and hard to fix in the
future. Having it as a separate step will make it more obvious that it occurs
and easier to maintain and grow. It also is logically not the same thing as
type checking.
Addressable Rules
All rules here assume that the expressions are of valid types for the operators
(e.g. that in ^EXP, EXP is a raw pointer type). The type checking can happen
after addressability is determined, because IDENTIFIERs are always addressable
and the result of dereferencing operation must be addressable. Addressability
can also be done after type checking, in which case it would be combined with
checking that the operands for place operators are addressable.
All expressions are Value expressions unless they satisify the Addressable
rules below. All other grammar rules are None.
X: IDENTIFIER
--------------
X :- Addressable
X: EXPRESSION :- Addressable
--------------
(X) :- Addressable
X: EXPRESSION :- Addressable, I: EXPRESSION
----------------
X[I] :- Addressable
X: EXPRESSION :- Addressable, F: IDENTIFIER
-----------------
X.F :- Addressable
X: EXPRESSION :- Addressable
----------------
@(const|mut) X :- Addressable
T: Type, X: *(const|mut) T
-----------------
^X :- Addressable
T: Type, X: *mut T
-----------------
^X :- Mutable
T: Type, X: *(const|mut) T
-----------------
X :- Addressable
X: EXPRESSION :- Addressable and Mutable, Y: Expression
----------------
mut X := Y :- Not Addressable
Array elements and structure fields are not de facto addressable. For example,
foo().field, the function foo returns a structure and we access the field
field. Within Bramble, we logically describe this as a value and not an addressable
expression so it cannot be used for @ or mutations. (Even though, in the LLVM
IR we generate we actually allocate space in the caller stack frame for the returned
structure value, we still logically describe it as a value expression, this is
because there is no label associated with it, so it would be hard for a user to
mentally or visually track how the value is being used or mutated).
Implementation
Status
Add an enumeration that has the variants: None|Value|Addressable|AddressableMutable
Add a field for this enumeration to SemanticContext with default value None.
Can I update canonize/foreach_mut to support POST order execution (as a configurable
flag)? If so, then I think I can use that foreach for the traversal? Part of
this would be updating foreach to do the Insight event recording too.
It might be easier to start out by adding this into type_resolver then move to its
own stage?
Update the grammar rules so that any expression can be used on teh LHS for mutation
and that any expression can be used as the operand for @(const|mut).
UX
The only impact on UX will be greater flexibility in what can be mutated and
referenced. So, this will move Bramble towards being more intuitive in that regard.
Insights
We should mark what expressions resolve to being addressable and what expressions
resolve to being only value expressions. This can be done by merging the events
generated by the addressability analysis with semantic node events via spans
tests.
A new compiler stage will be added to the trace output stage set: Addressability.
This stage will record the assignation of every span in the input source code with
whether it is Addressable or not. For each node in the AST that is checked, this
will emit an event with the result of the Addressability analysis.
Tests
- Test mutating an array element
- Test mutating a structure field
- Test referencing an array element
- Test referencing a field
- Test mutating a dereference (
mut ^a := 5)
- Test mutating an integer => fails
- Test mutating
(x+5) => fails
- Test
(x)
- Test
(x)[5].field, an array of structures
- Test
(x.field)[5], field is an array
- Test
^x.field, field is a pointer
- test
^x.field[2], field is an array of pointers
- Test
^x[0] array of pointers
- Mix in combinations of
()
8.3 - RFC 288 - MIR - Control Flow Graph
Use a Control Flow Graph as an IR to make implementation of rules that test data flow easier.
This RFC proposes using a Control Flow Graph (CFG) IR as a stage between the AST and LLVM forms, because it will help simplify the implementation of key Bramble features: including consistency semantics, ownership rules a la Rust, and automatic injection of destructors for values.
Bramble’s MIR language design was inspired by Rust’s MIR and the design of the conversion from AST to MIR was inspired by LLVM.
Problem
Bramble needs to perform data flow analysis on each function in a program. The analyses needed are: consistency rules checking, automatic insertion of destructors for values, and ownership rules. More analyses may be added in the future.
For each of these analyses, Bramble needs to look at the sequence of operations that are applied to one or more locations in memory, then determine if every possible sequence of operations satisfy some given set of rules. This is falls under dataflow analysis.
While an AST can be used for such analyses, it is not well suited and would make implementation of the analyses more complex.
Requirements
- Simplify the forms of analysis which follow a “dataflow” paradigm.
- Be able to lower into LLVM IR.
- Integrate with Thorn Insights platform.
- Be able to represent all Bramble programs in a MIR form.
- MIR representations must be fully independent of the preceding AST representation. This means that the AST form of a Bramble program could be deleted after conversion to MIR and the compilation will always be able to complete successfully.
- Allow for intra-procedure (local) optimizations.
Solution
Rather than use the AST IR for dataflow analyses, create a new Control Flow Graph IR (henceforth referred to as a MIR), and all dataflow analyses are done against this form rather than the AST form.
The AST will be “lowered” into the MIR form after parsing and type resolution and before transformation into the LLVM IR form. After being lowered, any analyses and optimizations which work best with a CFG are applied. Then the MIR is lowered into LLVM IR form and compilation continues with the LLVM compiler toolset.
Alternatives
The alternative solution is to continue using an AST for all compiler analyses and optimizations. Most compilers do their work off an AST form and only use CFG forms for optional optimizations or linting. The Rust compiler currently uses a CFG IR form as an intermediate step between the AST and LLVM IR; however, its earliest versions used only an AST and the CFG IR was added later to help simplify the ownership rules analysis.
The reason to continue using the AST for all analysis rather than the MIR is to save development time and simplify the implementation of rules and optimizations that focus on the flow of data. It is a fact that all analyses that work on the CFG IR model will work on an AST, but their implementation may be much more complex and fragile.
Problems with using an AST for this analysis include the following. First, all these analyses need to validate some rule holds for one or more variables through every possible path of execution, the AST form makes it difficult to correlate all the different paths when there are branches. Second, the AST form recursively embeds operators as children of operators, this makes it difficult to find the leaf operands (specifically the variables being used), because the desired analyses are focused largely on tracking how each specific variable is used, being able to easily extract those variables from operations is critical for easy implementation. Third, all these analyses will want to know what unbroken chain of operations must be applied to a set of variables (Basic Block), this information is difficult to extract from an AST. All this information is encoded in the AST form, but the AST form prioritizes preserving the hierarchy of operations, which obfuscates the information that the dataflow analyses require; this leads to the implementaion of analyzers being more complex.
The ulimate price of the increased complexity of implentation is reducing the power of the analyzers. As experienced by the Rust team when the lifetime checker was implemented on an AST: having a less powerful analyzer means more blunt enforcement of the rules. This pushes more burden onto the user of the language. In the case of Rust, the “more blunt” analyzer meant that it could not understand more complex or subtle memory operations and would fail code that was technically correct. Using the AST as the basis for dataflow analysis, leads to simpler analyzers, which leads to more false negatives, forcing users to write worse code.
I chose to implement the MIR because significantly reducing the complexity and fragility of the dataflow analyses will be a net long-term benefit for the Bramble compiler. The consistency rules system could be incredibly complex, as it evolves, and a CFG IR model will greatly reduce the complexity of its implementation. Further, many optimizations benefit from the CFG IR model and implementing one now will allow me to start safely adding optimizations to Bramble. Finally, this decision was influenced by taking advantage of Rust’s experience: using the AST IR form greatly limited the power of ownership rules system and moving to a CFG IR was critical for building a more powerful and useable ownership rules model. Given that the consistency rules model that Bramble will implement shares many mathematical fundamentals with Rust’s ownership model and lifetime model; Rust’s experience provides valid insight into a major pitfall Bramble could suffer.
Design
MIR Architecture Model
The Bramble MIR’s design represents a simplified model of the physical memory and CPU instructions. MIR breaks memory down into 3 locations, based upon their lifetime relative to the execution of a program: static, heap, and stack. All operations in the MIR correspond to a subset of the instructions on a CPU and, like a CPU, the results of each single operation must be stored somewhere before being used in a subsequent operation. Further, in MIR, operations are a linear sequence and have no hierarchy.
Static memory represents the “.data” and “.code” (For x86) sections of a program, which correspond the parts of memory where data lives from the moment the program begins execution to when it stops execution. In MIR, the representations of each function are stored in the “Static” memory group. Heap memory corresponds to the heap, and data here will live from the moment it is explicitly allocated until it is explicitly deallocated (currently, no constructs in MIR correspond to or represent heap data). Stack memory, or local memory, corresponds to the stack frame of a function: data in this section will be valid from the moment a function is entered to the moment that instance of the function exits. In MIR, all variables defined within a function (user and temporary) are stored on the stack.
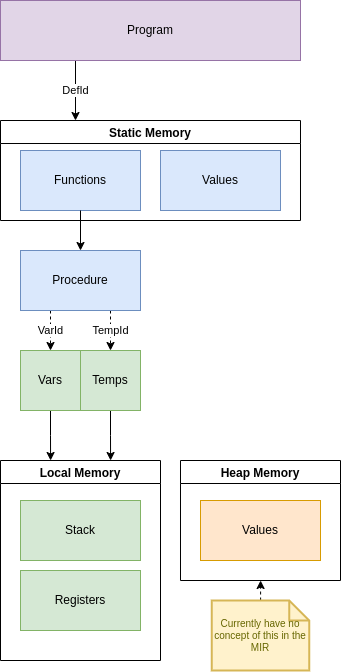
MIR Components
When lowered into its MIR form, a project is represented as a single MirProgram, which represents all the functions and types in the project. Each function is defined as a set of Basic Blocks. Each user defined type is stored as an ordered set of fields, where each field has a name and a type.
A Basic Block represent the largest set of operations where: if one operation is executed they are all executed and every operation is executed immediately after the preceding operation. Every Basic Block is composed of 0 or more Statements and a Terminator. The Statements represent operations that have results that are stored in memory. Terminators tell where the program will go after the last Statement in the Basic Block is executed.
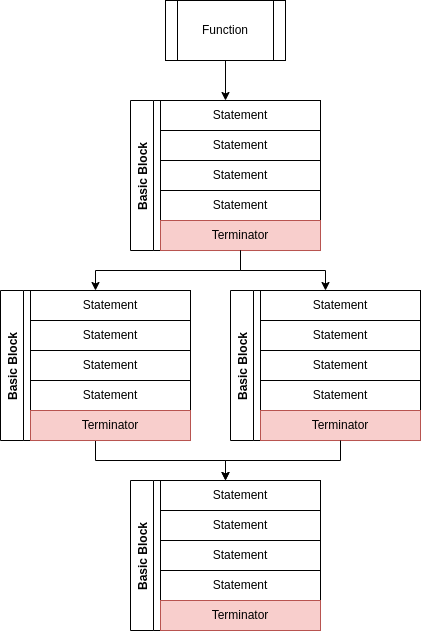
A visualizaiton of how a function with an If Expression would be represented via Basic Blocks. Each Basic Block is an ordered set of statements ending with a Terminator. The Terminator determines what the next Basic Block to be executed will be.
There is a single statement: Assign. This statement executes an operation and stores the result in a location in memory; this location can be either a user defined variable or a temporary variable for intermediate results. The operations correspond to unary and binary arithmetic instructions available on the CPU. Operations take one or two operands; operands can be either constants or specific locations in memory. Data can only be stored and read as base types (e.g., i32 or f64). For types constructed from base types (arrays and structs), Accessors are used to access the location of a specific element or field within a value of the constructed type.
The Terminator ends every Basic Block and is always executed. The simplest Terminator is the Return, which tells the program to exit the current function and remove its stack-frame from the stack. The GoTo Terminator tells the program to go to the specified Basic Block within the current function. The Conditional GoTo Terminator tells the program to go to one of two Basic Blocks based upon whether a given conditional value is true or false. Finally, the Call Terminator tells the program to call a function and provides a location to store the result of the function.
Lowering AST to MIR
The design for lowering the AST to the MIR resembles the current design for lowering the AST to LLVM IR. There is a set of MIR types that can represent any Bramble program in MIR and implement a CFG. The lowering process will generate a set of CFGs, composed of MIR values, that each represent a function from the input AST. The process uses a MIR Builder, which constructs the MIR form of a single function, and a Traverser, which traverses the AST and uses the Builder to convert types and functions into MIR forms.
The MirProgram type manages all custom types defined by the user and the MIR representation of each function. This is the final output of the lowering process. Subsequent operations that apply to the MIR will take the MirProgram as input.
The lowering process begins by traversing the AST for every user defined type and adds the type to the Type Table in MirProgram. Types are converted to MIR first, so that when they are encountered while lowering function definitions, their definitions can be easily found. This also separates responsibilities and leads to simpler code.
The Type Table assigns a unique integer identifier to each type and this identifier will be used within the MIR to represent types. This makes representation smaller in memory and makes programming easier and execution faster. Every type is represented by a single integer, so passing to other functions can be done by copying instead of cloning. Likewise, comparison will amount to a single integer comparison instruction. This will also lead to better Rust code.
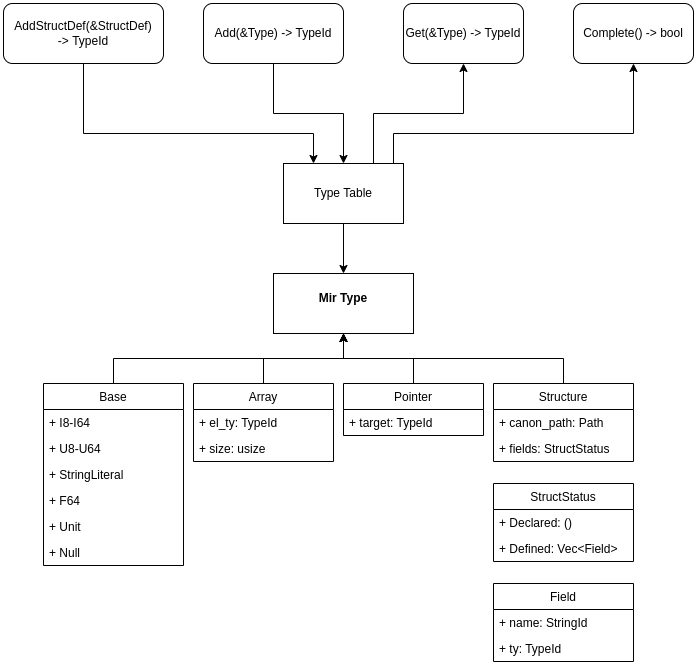
Note: The TypeTable is not strictly required: the MIR could continue to use Paths and the Structure Definitions in the AST form for referencing and looking up types. However, using an integer TypeId to identify types results in significantly simpler Rust code and is a better design overall. By taking this opportunity to add in the TypeTable we can begin to reap the benefits of this design and then, in the future, move the construction of the TypeTable to an earlier stage in the BrambleC pipeline so that the AST also uses TypeIds rather than the cumbersome Type enum.
After all types are lowered to the MIR, the AST is traversed again, and the name and signature of every defined function is added to the set of functions in MirProgram (without the MIR definition of the function). This is because functions are identified using integers in the MIR and we need to know the identifier for every function before lowering the function definitions, otherwise, there may be a call to a function that has not yet been lowered and it will not have an assigned function identifier.
After adding every function name and signature to the MirProgram and assigning them identifiers, the lowering process transforms the definition of each function from an AST to a MIR. A post order traversal of the AST of the function is performed and the Builder type is used to construct the MIR representation. After the function’s AST has been fully traversed the MIR is finalized and added to the MirProgram as the definition of the function. The lowering process is complete when every function has been converted into a MIR form.
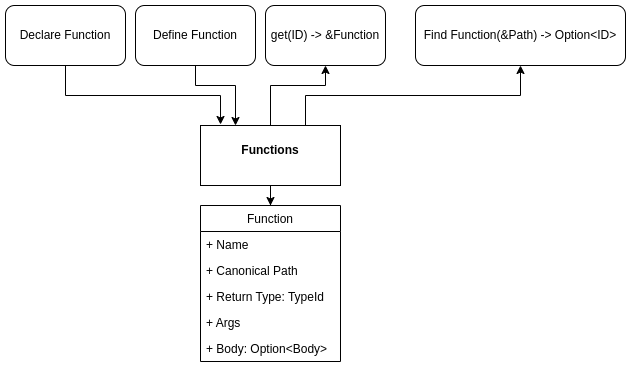
Lowering MIR to LLVM IR
After completing every test and transformation which relies upon the MIR form, the compiler lowers the final MIR into its LLVM form. The lowering process is split into two components: the Traverser and the Builder. The Traverser iterates over each function and custom type, and calls methods on the Builder to construct the LLVM IR. At the completion of the lowering process there will be an LLVM Module that contains all the types and functions in the Bramble project.
The Builder provides a set of methods that correspond to the MIR instruction set. The Traverser calls these methods as it encounters the corresponding MIR instructions. The methods cause the Builder to create the LLVM IR instructions that correspond to the Bramble MIR instructions.
The Builder is responsible for generating the labels for all custom types and all functions, that are used within the LLVM IR and, ultimately, the generated assembly code.
References
The main inspiration for the MIR was from reading through the Rust Compiler source code and this blog post: https://blog.rust-lang.org/2016/04/19/MIR.html. Much of the Bramble MIR design is directly inspired by Rust’s MIR, though a significantly simpler form.
The second source of inspiration was “Engineering a Compiler” by Keith Cooper and Linda Torczan. The chapters on dataflow analysis and control flow graphs directly led me to believe those concepts the best for implementing the consistency rules system for Bramble.
In addition, I looked at Clang and Rosalyn to understand how those compilers used Control Flow Graphs and how they designed their CFG models.
The following links were used during research for the MIR design:
- http://s4.ce.sharif.edu/blog/2019/12/31/clang/
- https://homepages.dcc.ufmg.br/~fernando/classes/dcc888/ementa/slides/ControlFlowGraphs.pdf
- https://eli.thegreenplace.net/2013/09/16/analyzing-function-cfgs-with-llvm
- https://docs.microsoft.com/en-us/dotnet/api/microsoft.codeanalysis.flowanalysis?view=roslyn-dotnet
- https://github.com/dotnet/roslyn-analyzers/blob/main/docs/Writing%20dataflow%20analysis%20based%20analyzers.md
- https://github.com/dotnet/roslyn/blob/1deafee3682da88bf07d1c18521a99f47446cee8/src/Compilers/Core/Portable/Operations/BasicBlock.cs
- https://github.com/rust-lang/rust/blob/f7ec6873ccfbf7dcdbd1908c0857c866b3e7087a/src/librustc/mir/repr.rs